The Learning Theory Alliance Blog: Testing Assumptions of Learning Algorithms
Today’s technical post is by Arsen Vasilyan. This focuses on the very exciting new “testable learning” he introduced with Rubinfeld in a 2023 paper. There’s been a flurry of work since then, so this is a good chance to catch up in case you’re behind!
1. The Goal: Learning with Noisy Labels
1.1 Introduction
Many learning algorithms simply stop working when some of the training examples are mislabeled. For example, suppose we are using a linear program to learn a linear classifier. Then, a single mislabeled data-point can make the linear program infeasible, and the algorithm fails to output a solution. Today, we will discuss how to design learning algorithms that are provably robust to such noise.
For noise-resistant learning algorithms, a key consideration emerges: what can these algorithms assume about how the data-points are distributed? We will discuss three theoretical frameworks addressing this question:
- Framework 1 — the distribution-free framework — makes no assumption on how data-points are generated. For every distribution over datapoints, the algorithm has to run efficiently and be robust to noise. This framework is very well-understood, but is computationally intractable. Even the simplest concept classes lead to computationally hard learning tasks in this framework.
- Framework 2 — the distribution-specific framework — assumes that data-points come from some well-behaved distribution, such as the Gaussian distribution. Over the last 30 years, the distribution-specific framework has led to a wealth of provably efficient algorithms. However, these algorithms fail to be noise-resistant when their assumptions do not hold.
- Framework 3 — the testable framework — relies on an assumption on the data-point distribution only for the run-time of an algorithm, but not for the algorithm’s robustness to noise. Even if data-points do not come from some well-behaved distribution, the algorithm should be robust to noise. However, in this case, the algorithm might take a long time to run.
This blog post will mostly focus on the third framework, which was recently introduced in [RV ’23] in the context of learning with noise, and further explored in [GKK ’23, DKKLZ ’23, GKSV ’23, GKSV ’24, GSSV ’24, DKLZ’24, STW ’24, GKSV ’25]. In brief, although Framework 3 is more stringent than Framework 2, there is a toolkit of techniques that we can use to upgrade many Framework 2 algorithms into Framework 3.
1.2 FAQ on the Testable Framework (Framework 3)
We get a lot of questions about Framework 3, and so we begin with the following FAQs:
-
Q: Why is the framework called testable?
A: All current algorithms in Framework 3 follow the following general recipe for upgrading Framework 2 algorithms into Framework 3 — the procedure suggests the name testable learning. See Section 2.2 for more about this recipe.- a) Run a Framework 2 algorithm and obtain a hypothesis
.
- b) Run a tester that is guaranteed to output “accept” whenever the assumption holds.
- c) If the tester accepted, return the hypothesis
- d) Otherwise, the assumption must have been violated so we can run a computationally expensive algorithm (See Section 1.3 for more about those).
- a) Run a Framework 2 algorithm and obtain a hypothesis
-
Q: To implement this tester, cant we just check that the distribution is “close” to a Gaussian using tools from distribution testing?
A: For many notions of “closeness” this is statistically impossible: for example one cannot test whether an unknown distribution is Gaussian or far from Gaussian in total variation distance.1 For other notions of closeness, such as the earth-mover distance, these tools require a number of samples and run-time that is exponential in the dimension. In learning theory, we are looking for much faster run-times (see [RV ’23] for more discussion). -
Q: What if the assumption is violated only slightly? I am concerned that this will cause a Framework 3 algorithm to run slowly as a result.
A: Many algorithms in Framework 3 can be modified to run fast whenever the assumption is only approximately satisfied in total variation distance [GKSV ’25]. This setting is called Tolerant Testable Learning, and discussed more in Section 3.2. -
Q: The algorithm is guaranteed to run fast for only one specific distribution. What if I want it to run fast for an entire family of distributions?
A: This setting, called universal testable learning, has also been studied. [GKSV ’23] studies it for the family of log-concave distributions, and it turns out to be intimately connected with Sum-of-Squares relaxations [KS17]. -
Q: Framework 3 is defined to work with learning under label noise (a.k.a. agnostic learning). What about (noise-free) PAC learning?
A: Frameworks 2 and 3 are essentially equivalent in the noise-free setting. In this setting, one can always tell whether the learning algorithm successfully produced a good hypothesis: just estimate its prediction error by drawing a fresh set of examples. If the prediction error is large, this must be because the assumption is violated, so Framework 3 does not require us to run fast. In this case, we can produce a classifier by running a computationally expensive algorithm (See Section 1.3 for more about those). -
Q: What is the sample complexity of this framework? Is it related to VC dimension?
A: [GKK ’23]have shown that the sample complexity of this model is characterized by the Rademacher complexity of the hypothesis class. However, in this blog post we will focus on the run-time rather than sample complexity.
We will now introduce the three frameworks in more detail, survey more of the known results and highlight general ideas for designing such algorithms.
1.3 Three Frameworks for Learning with Noisy Labels
Let us be more formal now. 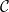


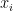


![\displaystyle \text{opt}{\mathcal{C}}:=\min{f\in\mathcal{C}}\underbrace{\Pr_{x\sim D_{\text{Examples}}}[f(x)\neq f_{\text{noisy labels}}(x)]}{\text{Prediction error of \ensuremath{f}.}}. ](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Ctext%7Bopt%7D%7B%5Cmathcal%7BC%7D%7D%3A%3D%5Cmin_%7Bf%5Cin%5Cmathcal%7BC%7D%7D%5Cunderbrace%7B%5CPr_%7Bx%5Csim+D_%7B%5Ctext%7BExamples%7D%7D%7D%5Bf%28x%29%5Cneq+f_%7B%5Ctext%7Bnoisy+labels%7D%7D%28x%29%5D%7D_%7B%5Ctext%7BPrediction+error+of+%5Censuremath%7Bf%7D.%7D%7D.+&bg=ffffff&fg=000000&s=0&c=20201002)
For instance,  denotes the smallest classification error achievable by any linear classifier.
Framework 1 [Distribution-free Framework] For any distribution 


![\displaystyle \overbrace{\Pr_{x\sim D_{\text{Examples}}}[h(x)\neq f_{\text{noisy labels}}(x)]}^{\text{Prediction error of \ensuremath{h}.}}\leq\underbrace{\overbrace{\text{opt}{\mathcal{C}}}^{\text{Optimal prediction error in \ensuremath{\mathcal{C}.}}}+\varepsilon}{\text{\ensuremath{\text{\text{\ensuremath{\text{Weaker guarantees, such as O(\ensuremath{\text{opt}{\mathcal{C}}})+\ensuremath{\varepsilon},\ also considered.}}}}}}}. ](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Coverbrace%7B%5CPr%7Bx%5Csim+D_%7B%5Ctext%7BExamples%7D%7D%7D%5Bh%28x%29%5Cneq+f_%7B%5Ctext%7Bnoisy+labels%7D%7D%28x%29%5D%7D%5E%7B%5Ctext%7BPrediction+error+of+%5Censuremath%7Bh%7D.%7D%7D%5Cleq%5Cunderbrace%7B%5Coverbrace%7B%5Ctext%7Bopt%7D_%7B%5Cmathcal%7BC%7D%7D%7D%5E%7B%5Ctext%7BOptimal+prediction+error+in+%5Censuremath%7B%5Cmathcal%7BC%7D.%7D%7D%7D%2B%5Cvarepsilon%7D_%7B%5Ctext%7B%5Censuremath%7B%5Ctext%7B%5Ctext%7B%5Censuremath%7B%5Ctext%7BWeaker+guarantees%2C+such+as+O%28%5Censuremath%7B%5Ctext%7Bopt%7D_%7B%5Cmathcal%7BC%7D%7D%7D%29%2B%5Censuremath%7B%5Cvarepsilon%7D%2C%5C+also+considered.%7D%7D%7D%7D%7D%7D%7D.+&bg=ffffff&fg=000000&s=0&c=20201002)
This task, also known as agnostic learning, can be solved sample-efficiently. According to a central theorem in the VC theory, 



However, when considering the run-time 

These intractability results hold for certain carefully-constructed worst-case choices of 
Framework 2 [Distribution-Specific Framework] For any distribution 
![\displaystyle \overbrace{\Pr_{x\sim D_{\text{Examples}}}[h(x)\neq f_{\text{noisy labels}}(x)]}^{\text{Prediction error of \ensuremath{h}.}}\leq\underbrace{\overbrace{\text{opt}{\mathcal{C}}}^{\text{Optimal prediction error in \ensuremath{\mathcal{C}.}}}+\varepsilon}{\text{\ensuremath{\text{\text{\ensuremath{\text{Weaker guarantees, such as O(\ensuremath{\text{opt}{\mathcal{C}}})+\ensuremath{\varepsilon},\ also considered.}}}}}}}. ](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Coverbrace%7B%5CPr%7Bx%5Csim+D_%7B%5Ctext%7BExamples%7D%7D%7D%5Bh%28x%29%5Cneq+f_%7B%5Ctext%7Bnoisy+labels%7D%7D%28x%29%5D%7D%5E%7B%5Ctext%7BPrediction+error+of+%5Censuremath%7Bh%7D.%7D%7D%5Cleq%5Cunderbrace%7B%5Coverbrace%7B%5Ctext%7Bopt%7D_%7B%5Cmathcal%7BC%7D%7D%7D%5E%7B%5Ctext%7BOptimal+prediction+error+in+%5Censuremath%7B%5Cmathcal%7BC%7D.%7D%7D%7D%2B%5Cvarepsilon%7D_%7B%5Ctext%7B%5Censuremath%7B%5Ctext%7B%5Ctext%7B%5Censuremath%7B%5Ctext%7BWeaker+guarantees%2C+such+as+O%28%5Censuremath%7B%5Ctext%7Bopt%7D_%7B%5Cmathcal%7BC%7D%7D%7D%29%2B%5Censuremath%7B%5Cvarepsilon%7D%2C%5C+also+considered.%7D%7D%7D%7D%7D%7D%7D.+&bg=ffffff&fg=000000&s=0&c=20201002)
This framework is also often referred to as distribution-specific agnostic learning. For many natural choices of distribution 
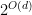

Yet, Framework 2 relies on the potentially unverifiable assumption that the distribution 
This limitation is addressed by the following more challenging framework, in which the algorithm must always output a near-optimal classifier (with high probability, as in Framework 1) but must run quickly only when the assumption holds (as in Framework 2):
Framework 3 [Testable Framework] For any distribution
![\displaystyle \overbrace{\Pr_{x\sim D_{\text{Examples}}}[h(x)\neq f_{\text{noisy labels}}(x)]}^{\text{Prediction error of \ensuremath{h}.}}\leq\underbrace{\overbrace{\text{opt}{\mathcal{C}}}^{\text{Optimal prediction error in \ensuremath{\mathcal{C}.}}}+\varepsilon}{\text{\ensuremath{\text{Weaker guarantees, such as O(\ensuremath{\text{opt}{\mathcal{C}}})+\ensuremath{\varepsilon},\ also considered.}}}}. \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Coverbrace%7B%5CPr%7Bx%5Csim+D_%7B%5Ctext%7BExamples%7D%7D%7D%5Bh%28x%29%5Cneq+f_%7B%5Ctext%7Bnoisy+labels%7D%7D%28x%29%5D%7D%5E%7B%5Ctext%7BPrediction+error+of+%5Censuremath%7Bh%7D.%7D%7D%5Cleq%5Cunderbrace%7B%5Coverbrace%7B%5Ctext%7Bopt%7D_%7B%5Cmathcal%7BC%7D%7D%7D%5E%7B%5Ctext%7BOptimal+prediction+error+in+%5Censuremath%7B%5Cmathcal%7BC%7D.%7D%7D%7D%2B%5Cvarepsilon%7D_%7B%5Ctext%7B%5Censuremath%7B%5Ctext%7BWeaker+guarantees%2C+such+as+O%28%5Censuremath%7B%5Ctext%7Bopt%7D_%7B%5Cmathcal%7BC%7D%7D%7D%29%2B%5Censuremath%7B%5Cvarepsilon%7D%2C%5C+also+considered.%7D%7D%7D%7D.+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
Furthermore, if
This framework is also often referred to as testable learning (for reasons explained in Section 2.2). When a Framework 3 algorithm produces a classifier

Even though Framework 3 requires more from the learning algorithm than Framework 2, a growing body of research demonstrates that Framework 3 is often as computationally tractable as Framework 2. This research direction was initiated in [RV ’23] which mainly considered linear classifiers under the Gaussian distribution, and was subsequently extended to many more hypothesis classes and distributions
2. How to Modify Framework 2 Algorithms to Work in Framework 3.
In this section we will discuss a general recipe for converting Framework 2 algorithms into Framework 3 by augmenting them with an appropriate tester. As a case study, we will focus on one of the most widely-studied Framework 2 algorithms: the Low-Degree Algorithm. We will see how it can be upgraded into Framework 3 using the Moment-Matching Tester. Later, in Section 3, we will see how a similar recipe can be used for other algorithms as well.
2.1 What is an Example of Framework 2 Algorithm? The Low-Degree Algorithm.
We begin by examining the following Framework 2 algorithm.
Degree-k Low-Degree Algorithm [KKMS ’08]:
Given: access to independent Gaussian examples labeled by unknown function 

Output: hypothesis 
-
{
Gaussian examples labeled by function
-
Compute
![\displaystyle p^{*}\leftarrow\underset{\boldsymbol{\text{degree}}-k\text{ polynomial }p}{\text{argmin}}\left[\mathbb{E}{(x{i},f_{\text{noisy labels}}(x_{i}))\sim S} p(x_{i})-f_{\text{noisy labels}}(x_{i}) \right] ](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+p%5E%7B%2A%7D%5Cleftarrow%5Cunderset%7B%5Cboldsymbol%7B%5Ctext%7Bdegree%7D%7D-k%5Ctext%7B+polynomial+%7Dp%7D%7B%5Ctext%7Bargmin%7D%7D%5Cleft%5B%5Cmathbb%7BE%7D_%7B%28x_%7Bi%7D%2Cf_%7B%5Ctext%7Bnoisy+labels%7D%7D%28x_%7Bi%7D%29%29%5Csim+S%7D%7Cp%28x_%7Bi%7D%29-f_%7B%5Ctext%7Bnoisy+labels%7D%7D%28x_%7Bi%7D%29%7C%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002) by solving a linear program.
- Output hypothesis
in
.
It can be shown [KKMS ’08, DGJSV ’10] that, for 

This approach also yields a classifier 
2.2 Converting the Low-Degree Algorithm into Framework 3 via the Moment-Matching Test.
For a wide range of concept classes 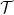
- Run6 an algorithm
for class
- Run some algorithm
- If
- If
for class

Let us compare Framework 2 and Framework 3, to see what specifications the tester
However, we can get away with less stringent requirements for
-
Completeness: whenever
-
Soundness: For all distributions
-optimality guarantee
![\displaystyle \overbrace{\Pr_{x\sim D_{\text{Examples}}}[h(x)\neq f_{\text{noisy labels}}(x)]}^{\text{Prediction error of \ensuremath{h}.}}\leq\overbrace{\text{opt}{\mathcal{C}}}^{\text{Optimal prediction error in \ensuremath{\mathcal{C}.}}}+\varepsilon. ](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Coverbrace%7B%5CPr%7Bx%5Csim+D_%7B%5Ctext%7BExamples%7D%7D%7D%5Bh%28x%29%5Cneq+f_%7B%5Ctext%7Bnoisy+labels%7D%7D%28x%29%5D%7D%5E%7B%5Ctext%7BPrediction+error+of+%5Censuremath%7Bh%7D.%7D%7D%5Cleq%5Coverbrace%7B%5Ctext%7Bopt%7D_%7B%5Cmathcal%7BC%7D%7D%7D%5E%7B%5Ctext%7BOptimal+prediction+error+in+%5Censuremath%7B%5Cmathcal%7BC%7D.%7D%7D%7D%2B%5Cvarepsilon.+&bg=ffffff&fg=000000&s=0&c=20201002)
-
Fast Run Time: the tester
The point of the Soundness condition is to permit the algorithm
Let us come back to using the recipe above, taking
Degree-
- Given: access to independent examples from
- Output: Accept or Reject.
-
- For all monomials
of total degree at most
- If
, output Reject and terminate.
(Note: For many distributionscan be computed directly. One can also draw samples from
- If
- If this step is reached, output Accept.
Since in 
Overall, using the recipe above to combine the degree-
The proof of correctness for these algorithms in Framework 3 is far from automatic. As explained in Section 2.3, the notion of sandwiching polynomials from the field of pseudorandomness turns out to be very important for the proof of correctness [GKK ’23].
Remark: many papers referenced here phrase their main result as a tester
2.3 Analysis of the Moment-Matching Tester through Sandwiching Polynomials.
Soon, we will discuss more Framework 3 algorithms, but let us first discuss the proof of correctness for the Moment-Matching Tester. Recall that it needs to satisfy three conditions: Completeness, Soundness and Fast Run Time. Among these three, the Soundness condition is the most challenging one to prove. [GKK ’23] give a principled way of doing this, which we will briefly sketch now. A key step is to show that every function 

-
Sandwiching: for every point
.
-
.
For example, linear classifiers have 
![{\mathbb{E}_{x\sim D_{\text{Assumption}}}[f(x)]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D_%7Bx%5Csim+D_%7B%5Ctext%7BAssumption%7D%7D%7D%5Bf%28x%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
It is shown in [GKK ’23] that whenever such a pair of polynomials exists for every 
If the distribution 
![{\mathbb{E}_{x\sim D_{\text{Assumption}}}[m(x)]\approx\mathbb{E}_{x\sim D_{\text{Examples}}}[m(x)]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D_%7Bx%5Csim+D_%7B%5Ctext%7BAssumption%7D%7D%7D%5Bm%28x%29%5D%5Capprox%5Cmathbb%7BE%7D_%7Bx%5Csim+D_%7B%5Ctext%7BExamples%7D%7D%7D%5Bm%28x%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
| ![\displaystyle \mathbb{E}{x\sim D{\text{Examples}}}\left[\left | f^{*}(x)-p_{\text{down}}(x)\right | \right] \ \leq\mathbb{E}{x\sim D{\text{Examples}}}[p_{\text{up}}(x)-p_{\text{down}}(x)]\approx\mathbb{E}{x\sim D{\text{Assumption}}}[p_{\text{up}}(x)-p_{\text{down}}(x)]\leq\varepsilon, ](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BE%7D_%7Bx%5Csim+D_%7B%5Ctext%7BExamples%7D%7D%7D%5Cleft%5B%5Cleft%7Cf%5E%7B%2A%7D%28x%29-p_%7B%5Ctext%7Bdown%7D%7D%28x%29%5Cright%7C%5Cright%5D+%5C%5C+%5Cleq%5Cmathbb%7BE%7D_%7Bx%5Csim+D_%7B%5Ctext%7BExamples%7D%7D%7D%5Bp_%7B%5Ctext%7Bup%7D%7D%28x%29-p_%7B%5Ctext%7Bdown%7D%7D%28x%29%5D%5Capprox%5Cmathbb%7BE%7D_%7Bx%5Csim+D_%7B%5Ctext%7BAssumption%7D%7D%7D%5Bp_%7B%5Ctext%7Bup%7D%7D%28x%29-p_%7B%5Ctext%7Bdown%7D%7D%28x%29%5D%5Cleq%5Cvarepsilon%2C+&bg=ffffff&fg=000000&s=0&c=20201002) |
where the first step uses the sandwiching property, the second step breaks 
| Finally, the upper bound on ![{\mathbb{E}{x\sim D{\text{Examples}}}\left[\left | f^{*}(x)-p_{\text{down}}(x)\right | \right]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D_%7Bx%5Csim+D_%7B%5Ctext%7BExamples%7D%7D%7D%5Cleft%5B%5Cleft%7Cf%5E%7B%2A%7D%28x%29-p_%7B%5Ctext%7Bdown%7D%7D%28x%29%5Cright%7C%5Cright%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) tells us that the Low-Degree Algorithm finds a polynomial  with with |
| ![\displaystyle \frac{1}{2}\mathbb{E}{x\sim D{\text{Examples}}}\left[\left | f_{\text{noisy labels}}(x)-p^{*}(x)\right | \right]\lesssim\frac{1}{2}\mathbb{E}{x\sim D{\text{Examples}}}\left[\left | f_{\text{noisy labels}}(x)-p_{\text{down}}(x)\right | \right] \lesssim \ \underbrace{\frac{1}{2}\mathbb{E}{x\sim D{\text{Examples}}}\left[\left | f_{\text{noisy labels}}(x)-f^{*}(x)\right | \right]}{=\text{opt}{\mathcal{C}}\text{ because } f^{*} \text{ is best classifier in }\mathcal{C}+\varepsilon}. ](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cfrac%7B1%7D%7B2%7D%5Cmathbb%7BE%7D_%7Bx%5Csim+D_%7B%5Ctext%7BExamples%7D%7D%7D%5Cleft%5B%5Cleft%7Cf_%7B%5Ctext%7Bnoisy+labels%7D%7D%28x%29-p%5E%7B%2A%7D%28x%29%5Cright%7C%5Cright%5D%5Clesssim%5Cfrac%7B1%7D%7B2%7D%5Cmathbb%7BE%7D_%7Bx%5Csim+D_%7B%5Ctext%7BExamples%7D%7D%7D%5Cleft%5B%5Cleft%7Cf_%7B%5Ctext%7Bnoisy+labels%7D%7D%28x%29-p_%7B%5Ctext%7Bdown%7D%7D%28x%29%5Cright%7C%5Cright%5D+%5Clesssim+%5C%5C+%5Cunderbrace%7B%5Cfrac%7B1%7D%7B2%7D%5Cmathbb%7BE%7D_%7Bx%5Csim+D_%7B%5Ctext%7BExamples%7D%7D%7D%5Cleft%5B%5Cleft%7Cf_%7B%5Ctext%7Bnoisy+labels%7D%7D%28x%29-f%5E%7B%2A%7D%28x%29%5Cright%7C%5Cright%5D%7D_%7B%3D%5Ctext%7Bopt%7D_%7B%5Cmathcal%7BC%7D%7D%5Ctext%7B+because+%7D+f%5E%7B%2A%7D+%5Ctext%7B+is+best+classifier+in+%7D%5Cmathcal%7BC%7D%2B%5Cvarepsilon%7D.+&bg=ffffff&fg=000&s=0&c=20201002) |
3. Going Beyond Low-Degree Algorithm.
To recap: in Framework 2, the Low-Degree Algorithm works for many hypothesis classes
- Run-time for the Low-Degree Algorithm tends to be exponential in
. For example, to get error , the Low-Degree Algorithms needs to run in time
- The algorithms are improper, which means the hypothesis
- (a) We get a labeled data-set
, and we want to fit approximately the best linear classifier to
- (b) We get a labeled data set
where
is some polynomial, this classifier should approximately be as good as the best linear classifier on
.
- (a) We get a labeled data-set
We will now discuss subsequent work that focuses on removing these limitations.
3.1 The Matter of Efficiency: Polynomial-Time Algorithms in Framework 3.
3.1.1 Learning Beyond Low-Degree Algorithm.
In contrast with the Low-Degree Algorithm, some algorithms in Framework 2 are tailor-made for specific classes
Averaging Algorithm [KKMS ’08]:
- Given: access to independent standard Gaussian examples
- Output: hypothesis
.
-
-
.
- Output

When the distribution 





![\displaystyle w=\sum_{x_{i}\in S}\left[f_{\text{noisy labels}}(x_{i})\cdot x_{i}\right]= \underbrace{\sum_{x_{i}\in S}\left[\text{sign}(w^{*}\cdot x_{i})\cdot x_{i}\right]} _{\text{Signal term: }w_{\text{signal}}} + \underbrace{\sum_{x_{i}\in S}\left[(f_{\text{noisy labels}}(x_{i})-\text{sign}(w^{*}\cdot x_{i}))\cdot x_{i}\right]}_{\text{Noise term: }w_{\text{noise}}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++w%3D%5Csum_%7Bx_%7Bi%7D%5Cin+S%7D%5Cleft%5Bf_%7B%5Ctext%7Bnoisy+labels%7D%7D%28x_%7Bi%7D%29%5Ccdot+x_%7Bi%7D%5Cright%5D%3D+%5Cunderbrace%7B%5Csum_%7Bx_%7Bi%7D%5Cin+S%7D%5Cleft%5B%5Ctext%7Bsign%7D%28w%5E%7B%2A%7D%5Ccdot+x_%7Bi%7D%29%5Ccdot+x_%7Bi%7D%5Cright%5D%7D+_%7B%5Ctext%7BSignal+term%3A+%7Dw_%7B%5Ctext%7Bsignal%7D%7D%7D+%2B+%5Cunderbrace%7B%5Csum_%7Bx_%7Bi%7D%5Cin+S%7D%5Cleft%5B%28f_%7B%5Ctext%7Bnoisy+labels%7D%7D%28x_%7Bi%7D%29-%5Ctext%7Bsign%7D%28w%5E%7B%2A%7D%5Ccdot+x_%7Bi%7D%29%29%5Ccdot+x_%7Bi%7D%5Cright%5D%7D_%7B%5Ctext%7BNoise+term%3A+%7Dw_%7B%5Ctext%7Bnoise%7D%7D%7D+&bg=ffffff&fg=000&s=0&c=20201002)
arguing10 as follows:
-
For a Gaussian dataset will be at most
is likely to be large while the inner product with directions orthogonal to
will likely be much smaller. Likewise, the norm  can be shown to be close to  with high probability. -
Since the classifier of size  satisfies ![\displaystyle \left \sum_{x_{i}\in S’}\left[x_{i}\right]\right \leq\left(\tilde{O}\left(\alpha\right)+\varepsilon\right) S . ](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%7C%5Csum_%7Bx_%7Bi%7D%5Cin+S%27%7D%5Cleft%5Bx_%7Bi%7D%5Cright%5D%5Cright%7C%5Cleq%5Cleft%28%5Ctilde%7BO%7D%5Cleft%28%5Calpha%5Cright%29%2B%5Cvarepsilon%5Cright%29%7CS%7C.+&bg=ffffff&fg=000000&s=0&c=20201002) This lets us upper-bound the norm  with . -
Steps (a) and (b) together can be used to conclude that

We now use the bound on the angle
to bound how much less accurate the classifier
can be compared to
. Indeed, for a Gaussian sample
is
, which allows us to conclude that
![\displaystyle \Pr_{x\sim D_{\text{Examples}}}[\text{sign}(w{\cdot x})\neq f_{\text{noisy labels}}(x)]\leq\ \underbrace{\Pr_{x\sim D_{\text{Examples}}}[\text{sign}(w^{}{\cdot x})\neq\text{sign}(w{\cdot x})]}_{=\Theta(\angle(w,w^{}))\leq\tilde{O}(\text{opt}{\mathcal{C}})+\varepsilon}+\underbrace{\Pr{x\sim D_{\text{Examples}}}[\text{sign}(w^{*}{\cdot x})\neq f_{\text{noisy labels}}(x)]}{=\text{opt}{\mathcal{C}}}=\tilde{O}(\text{opt}{\mathcal{C}})+\varepsilon. ](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5CPr%7Bx%5Csim+D_%7B%5Ctext%7BExamples%7D%7D%7D%5B%5Ctext%7Bsign%7D%28w%7B%5Ccdot+x%7D%29%5Cneq+f_%7B%5Ctext%7Bnoisy+labels%7D%7D%28x%29%5D%5Cleq%5C%5C+%5Cunderbrace%7B%5CPr_%7Bx%5Csim+D_%7B%5Ctext%7BExamples%7D%7D%7D%5B%5Ctext%7Bsign%7D%28w%5E%7B%2A%7D%7B%5Ccdot+x%7D%29%5Cneq%5Ctext%7Bsign%7D%28w%7B%5Ccdot+x%7D%29%5D%7D_%7B%3D%5CTheta%28%5Cangle%28w%2Cw%5E%7B%2A%7D%29%29%5Cleq%5Ctilde%7BO%7D%28%5Ctext%7Bopt%7D_%7B%5Cmathcal%7BC%7D%7D%29%2B%5Cvarepsilon%7D%2B%5Cunderbrace%7B%5CPr_%7Bx%5Csim+D_%7B%5Ctext%7BExamples%7D%7D%7D%5B%5Ctext%7Bsign%7D%28w%5E%7B%2A%7D%7B%5Ccdot+x%7D%29%5Cneq+f_%7B%5Ctext%7Bnoisy+labels%7D%7D%28x%29%5D%7D_%7B%3D%5Ctext%7Bopt%7D_%7B%5Cmathcal%7BC%7D%7D%7D%3D%5Ctilde%7BO%7D%28%5Ctext%7Bopt%7D_%7B%5Cmathcal%7BC%7D%7D%29%2B%5Cvarepsilon.+&bg=ffffff&fg=000&s=0&c=20201002)
A series of subsequent works developed new algorithms, improving the prediction error to  [ABL ’14, DKTZ ’20, DKTZ ’22]. Also, unlike the Low-Degree Algorithm, these algorithms are proper, i.e. the hypothesis
However, all these algorithms inherently operate in Framework 2 rather than Framework 3, relying on the Gaussianity assumption not only for their run-time but also for their accuracy guarantee. For example, we can see that all three aforementioned steps — (a), (b) and (c) — in the accuracy analysis of the Averaging Algorithm use Gaussianity in crucial ways.
3.1.2 Modified Moment-Matching Tester.
Can we again use the recipe from Section 2.2 and the Moment-Matching Tester to get a
Surprisingly, a modified version of the Moment-Matching Tester can nevertheless be used in this way. First, we run one of these algorithms and obtain a hypothesis 
Strip Tester [DKKLZ ’23, GKSV ’23, GKSV ’24]:
- Given: access to independent examples from
- Output: Accept or Reject.
-
- For all monomials
and integers
:
-
Define
![\displaystyle \mathbf{1}{w\cdot x\in[i\varepsilon,(i+1)\varepsilon]}=\begin{cases} 1 & \text{if }w\cdot x\in[i\varepsilon,(i+1)\varepsilon]\ 0 & \text{otherwise.} \end{cases} ](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbf%7B1%7D%7Bw%5Ccdot+x%5Cin%5Bi%5Cvarepsilon%2C%28i%2B1%29%5Cvarepsilon%5D%7D%3D%5Cbegin%7Bcases%7D+1+%26+%5Ctext%7Bif+%7Dw%5Ccdot+x%5Cin%5Bi%5Cvarepsilon%2C%28i%2B1%29%5Cvarepsilon%5D%5C%5C+0+%26+%5Ctext%7Botherwise.%7D+%5Cend%7Bcases%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
-
If ![{\lvert\mathbb{E}{x\sim S}[m(x)\mathbf{1}{w\cdot x\in[i\varepsilon,(i+1)\varepsilon]}]-\mathbb{E}{x\sim D{\text{Assumption}}}[m(x)\mathbf{1}{w\cdot x\in[i\varepsilon,(i+1)\varepsilon]}]\rvert>\left(\varepsilon/d\right)^{O(1)}}](https://s0.wp.com/latex.php?latex=%7B%5Clvert%5Cmathbb%7BE%7D%7Bx%5Csim+S%7D%5Bm%28x%29%5Cmathbf%7B1%7D_%7Bw%5Ccdot+x%5Cin%5Bi%5Cvarepsilon%2C%28i%2B1%29%5Cvarepsilon%5D%7D%5D-%5Cmathbb%7BE%7D_%7Bx%5Csim+D_%7B%5Ctext%7BAssumption%7D%7D%7D%5Bm%28x%29%5Cmathbf%7B1%7D_%7Bw%5Ccdot+x%5Cin%5Bi%5Cvarepsilon%2C%28i%2B1%29%5Cvarepsilon%5D%7D%5D%5Crvert%3E%5Cleft%28%5Cvarepsilon%2Fd%5Cright%29%5E%7BO%281%29%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002), output Reject and terminate.
-
- If this step is reached, output Accept.
Essentially, the algorithm above breaks the
Combining this Strip Tester with the Framework 2 algorithm of [DKTZ ’20], yields an algorithm in Framework 3 with prediction error  and run-time
Moreover, like the Averaging Algorithm, this algorithm is proper, i.e. the hypothesis
3.2 Assumption-Tolerance and the Spectral Tester.
Finally, we briefly discuss some recent work on addressing the third limitation of the Moment-Matching Tester described in the beginning of Section 3. To recap, the limitation is that the Moment-Matching Tester might reject distributions that are very close to the distribution
Framework 4 [Tolerant Testable Framework] For any 
![\displaystyle \overbrace{\Pr_{x\sim D_{\text{Examples}}}[h(x)\neq f_{\text{noisy labels}}(x)]}^{\text{Prediction error of \ensuremath{h}.}}\leq\underbrace{\overbrace{\text{opt}{\mathcal{C}}}^{\text{Optimal prediction error in \ensuremath{\mathcal{C}.}}}+\varepsilon}{\text{\ensuremath{\text{Weaker guarantees such as O(\ensuremath{\text{opt}{\mathcal{C}}})+\ensuremath{\varepsilon\ }also considered.}}}}. \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Coverbrace%7B%5CPr%7Bx%5Csim+D_%7B%5Ctext%7BExamples%7D%7D%7D%5Bh%28x%29%5Cneq+f_%7B%5Ctext%7Bnoisy+labels%7D%7D%28x%29%5D%7D%5E%7B%5Ctext%7BPrediction+error+of+%5Censuremath%7Bh%7D.%7D%7D%5Cleq%5Cunderbrace%7B%5Coverbrace%7B%5Ctext%7Bopt%7D_%7B%5Cmathcal%7BC%7D%7D%7D%5E%7B%5Ctext%7BOptimal+prediction+error+in+%5Censuremath%7B%5Cmathcal%7BC%7D.%7D%7D%7D%2B%5Cvarepsilon%7D_%7B%5Ctext%7B%5Censuremath%7B%5Ctext%7BWeaker+guarantees+such+as+O%28%5Censuremath%7B%5Ctext%7Bopt%7D_%7B%5Cmathcal%7BC%7D%7D%7D%29%2B%5Censuremath%7B%5Cvarepsilon%5C+%7Dalso+considered.%7D%7D%7D%7D.+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002)
Furthermore, for some absolute constant 

In [GSSV ’24], a general methodology is developed for designing algorithms in this more general framework. For example, when
In brief, one of the key insights is that the degree-
![\displaystyle \max_{\text{degree}-k\text{ polynomial }p}\mathbb{E}_{x\sim S}[(p(x))^{2}]\leq O(1)\mathbb{E}_{x\sim D_{\text{Assumption}}}[(p(x))^{2}].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmax_%7B%5Ctext%7Bdegree%7D-k%5Ctext%7B+polynomial+%7Dp%7D%5Cmathbb%7BE%7D_%7Bx%5Csim+S%7D%5B%28p%28x%29%29%5E%7B2%7D%5D%5Cleq+O%281%29%5Cmathbb%7BE%7D_%7Bx%5Csim+D_%7B%5Ctext%7BAssumption%7D%7D%7D%5B%28p%28x%29%29%5E%7B2%7D%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)
The second insight is that the degree-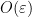
4. Other recent work.
This blog post focused on side-stepping the intractability of Framework 1 via making assumptions on the distribution 
The work of [STW ’24] shows how to use the Low-Degree Algorithm and the Moment-Matching Tester to get algorithms in Framework 3 for the challenging hypothesis class of polynomial threshold functions.
The work of [GKSV ’23] extends Framework 3 to families of distributions. Rather than being required to run in time
[KKV24, GSSV’24, CKKSV’24, KSV’24] build on the approaches described here to test distribution shift, i.e. to test that the unlabeled data found during deployment of a classifier
5. Open Problems.
There are unsolved problems for all three frameworks we discussed today. Even in Framework 1, where there are still large gaps in our understanding of some basic problems:
Open problem 1: Is there an algorithm in Framework 1 with accuracy  and run-time bound 


To the best of our understanding, assuming the Exponential Time Hypothesis, the NP-hardness results of [GR’06, FGKP’06] imply that no
The following is an open question in Framework 2:
Open problem 2: Is there an algorithm in Framework 2 with accuracy  and run-time bound 
For a long time, we have had algorithms with run-time 
Finally, the following is an open question in Framework 3:
Open problem 3: Is there an algorithm in Framework 3 with accuracy  and run-time bound
Note that [DKLZ’24] gives an algorithm with a run-time bound
Acknowledgements
We are grateful to Gautam Kamath, Adam Klivans, and Ronitt Rubinfeld for their valuable feedback on a draft of this blog post.
Footnotes
- A proof sketch: Draw $latex {N^{2}}&fg=000000$ samples $latex {S}&fg=000000$ from the Gaussian distribution and let $latex {D_{\text{sub-sample}}}&fg=000000$ be uniform over $latex {S}&fg=000000$. The distribution $latex {D_{\text{sub-sample}}}&fg=000000$ is $latex {\Omega(1)}&fg=000000$-far from Gaussian in total variation distance, but it can be shown that $latex {\Omega(N)}&fg=000000$ samples are necessary to distinguish such $latex {D_{\text{sub-sample}}}&fg=000000$ from the Gaussian distribution. We can take $latex {N}&fg=000000$ to be arbitrarily large, so no finite-sample tester exists.
 ︎
︎
- One can also consider labels $latex {\left{ y_{i}\right} }&fg=000000$ that are themselves random variables rather than a deterministic function of example $latex {x}&fg=000000$. Everything is this blog post will apply to that setting as well. ︎
- Throughout blog post, we will assume a success probability of (say) $latex {0.99}&fg=000000$. This probability can be improved to $latex {1-\delta}&fg=000000$ by repeating the process $latex {\log1/\delta}&fg=000000$ times and selecting the classifier that does best on a fresh set of samples. ︎
- Note: even for this easier task, no algorithm is known in Framework 2 with run-time better than $latex {2^{O(d)}}&fg=000000$. ︎
- Henceforth, for simplicity, when we say “a Framework 3 algorithm $latex {\mathcal{A}}&fg=000000$ runs in time $latex {T}&fg=000000$” we really mean “$latex {\mathcal{A}}&fg=000000$ runs in time $latex {T}&fg=000000$ when $latex {D_{\text{Examples}}=D_{\text{Assumption}}}&fg=000000$” as Framework 3 does not require a run-time bound when $latex {D_{\text{Examples}}\neq D_{\text{Assumption}}}&fg=000000$. ︎
- If the algorithm runs longer than $latex {T}&fg=000000$ or fails to output a classifier, stop and go to last step. ︎
- The tester below generalizes the tester of [AGM ’03, AAKMRX ’07, OZ ’18] for testing $latex {k}&fg=000000$-wise independence. ︎
- Inspecting the general recipe described in this section, we see that, strictly speaking, to execute this recipe one needs not only a tester $latex {\mathcal{T}}&fg=000000$ but also an algorithm $latex {\mathcal{A}’}&fg=000000$ for class $latex {\mathcal{C}}&fg=000000$ in Framework 1 (which is allowed to be very slow). Existence of such $latex {\mathcal{A}’}&fg=000000$ is a very mild condition and holds for all concept classes $latex {\mathcal{C}}&fg=000000$ for which this problem has been considered. ︎
- To do this, one needs to show that none of the coefficients of $latex {p_{\text{up}}(x)-p_{\text{down}}(x)}&fg=000000$ is too large, which turns out to be true. ︎
- For the rest of this subsection we will refer to Standard Gaussian distribution as simply Gaussian and origin-centered linear classifiers as simply linear classifiers. ︎
- The definition is inspired by the setting of tolerant property testing [PRR06]. ︎
- This last insight is closely related to the method used in [DKS18] to solve a different problem. ︎
By avasilyan